RNA Genomes and Modern Virology
RNA as genetic material
While it had been known since Bawden and Pirie’s work in 1937 that TMV particles contained RNA, followed later by a number of other viruses, it must be remembered that DNA had only really been accepted as the genetic material of cells and viruses after the Hershey-Chase experiment in 1952 and the Watson-Crick demonstration of the nature of DNA in 1953. Moreover, the way in which the information in DNA was used to make proteins was still very obscure in the 1950s, given that the proof that RNA was used as a template for the production of proteins was only provided in 1961 by Marshall Nirenberg.
It was hailed as a major development in molecular biology, therefore, when between 1955 and 1957, Heinz Fraenkel-Conrat, B Singer and Robley C Williams demonstrated that it was possible to reconstitute fully infectious TMV from separately-purified preparations of coat protein and RNA. At the time it was assumed that neither of the two components was infectious on its own; however it was subsequently shown by Fraenkel-Conrat and Singer, and separately by A Gierer and G Schramm, that purified TMV RNA was in fact infectious – albeit several hundred times more weakly per unit mass than the native or reconstituted particles.
While this was revolutionary in itself, the clinching experiment was the proof that mixed reconstitution – or the reassembly of a RNA of one strain of TMV with the coat protein of another – followed by infection of plants resulted in particles made of protein specified by the RNA component rather than being determined by the protein donor. This work possibly represents the birth of molecular virology as a sub-discipline within molecular biology, given that the molecular nature of viruses had so conclusively been shown – vindicating the prescient remark made by the virus pioneer Thomas Rivers in 1941, on the occasion of the presentation of a gold medal to Wendell Stanley, that:
“In fun, it has been said that we do not know whether to speak of the unit of this infectious agent [TMV] as an “organule” or a “molechism”” (p.7, CA Knight, Chemistry of Viruses 2nd Edn., 1975. Springer-Verlag, Wien)
Further important developments with TMV included the demonstration in 1958 by Gierer and KW Mundry that TMV mutants with altered genomes could be produced by treatment of virions with nitrous acid, which only alters nucleic acids, and the sequencing of the TMV coat protein in 1960 by two groups including Fraenkel-Conrat and Stanley and Knight in one, and Schramm in the other.
Between 1953 and 1954, an interesting class of new viruses was discovered in humans, birds, and later in other animals too. These were dubbed “respiratory enteric orphans” based on where they were found, and the fact they were not associated with any disease – which gave rise to the name “reovirus”, and their description as a distinct group of viruses by
Human rotavirus, in the family Reoviridae. Russell Kightley Media
Albert Sabin in 1959. By 1962 the unique double-layered capsid morphology had been seen and the virions shown to contain RNA, and then in 1963 PJ Gomatos and I Tamm showed using physical and chemical techniques that the viruses as well as the similar wound tumour virus isolated from plants had a genome consisting of double-stranded (ds) RNA – a finding unprecedented in biology at the time. Gomatos and W Stoeckenius went on to show in 1964 – by electron microscopy – that the reovirus genome was also segmented – another unprecedented finding for viruses. In the 1963 paper the authors remark that “…all attempts to isolate the nucleic acid of reovirus in an infective form have failed” – which distinguished these viruses from the ssRNA viruses previously looked at – not surprisingly, given the requirement for a different replication method for dsRNA compared to viruses like TMV or poliovirus (see here).
Ribosomes translating protein from a messenger RNA molecule
A major highlight in molecular biology in 1961 was Marshall Nirenberg and Heinrich Matthaei’s 1961 demonstration of “…an assay system in which RNA serves as an activator of protein synthesis in E. coli extracts”, or the proof in an in vitro translation system that RNA was the “messenger” that conveyed genetic information into proteins.
In 1962, A Tsugita, Fraenkel-Conrat, Nirenberg and Matthaei used the still extremely novel in vitro translation system with purified TMV genomic RNA, and were able to show that:
“The addition of TMV-RNA to a cell-free amino acid incorporating system derived from E. coli caused up to 75-fold stimulation in protein synthesis (C14-incorporation). Part of the protein synthesized formed a specific precipitate with anti-TMV serum.”, indicating that TMV coat protein had been made.
This was the first demonstration of in vitro translation from any specific mRNA, and incidentally also direct proof that the single-stranded TMV genome was “messenger sense”. They also concluded that their result showed that the newly-determined “genetic code” – the nucleotide triplets that code for individual amino acids – was universal, given that it was a tobacco virus RNA being translated by a bacterial system.
Later in 1962, D Nathans and colleagues used coliphage f2 RNA as template for translation in the same type of bacterial extract. They showed that polypeptides corresponding to the coat as well as other proteins were made, showing that it was the input virion RNA that was responsible.
Modern virology
The proof that RNA was both the “messenger” that conveyed information from DNA to be made into protein, and was in fact a genetic material in its own right, made possible a revolution in virology that transformed it into the science we know today. The new molecular biology together with well-established physical and biochemical techniques for molecular characterisation, coupled with the ability to reliably culture bacterial, plant and now animal viruses as well, enabled an explosion of discovery that continues to this day.
A tour de force experiment in the modern molecular biological era was the in vitro synthesis of an infectious phage RNA genome by S Spiegelman and coworkers in 1965, using only purified Qbeta coliphage single-stranded virion RNA and the purified viral replicase. They remarked:
“The successful synthesis of a biologically active nucleic acid with a purified enzyme is itself of obvious interest. However, the implication which is most pregnant with potential usefulness stems from the demonstration that the replicase is, in fact, generating identical copies of the viral RNA. For the first time, a system has been made available which permits the unambiguous analysis of the molecular basis underlying the replication of a self-propagating nucleic acid.”
In 1967 there followed the demonstration that the same could be done for a single-stranded (ss)-DNA virus: M Goulian and colleagues reported in that they had successfully made a completely synthetic and infectious PhiX174 coliphage genome, by means of a series of syntheses using purified virion ssDNA, E coli DNA polymerase and a “polynucleotide-joining enzyme”, or DNA ligase. It is instructive that the authors offer this as evidence for the involvement of the same enzymes in E coli chromosomal replication, the mechanism for which which was still obscure at the time. Their justification for their work:
“If enzymatic synthesis of infectious bacteriophage DNA were achieved, it would be made clear at once that relatively few, if any, mistakes had been made in replicating a DNA sequence of several thousand nucleotides.”
– was undoubtedly borne out, in yet another example in the growing number of cases of the use of viruses to demonstrate important facets of cellular biology.
Naked nucleic acids as infectious agents: viroids
A potato disease that had been known in the New York and New Jersey state areas in the US since the 1920s was the source of an exciting discovery by Theodor (Ted) Diener and WB Raymer, reported in Science in 1967. The potato spindle tuber disease agent had proved recalcitrant over many years to being characterised or isolated; all that was known was that it could be transmitted mechanically using sap, or via grafting, and that no fungi, bacteria or viruses could be isolated from diseased material. Diener and Raymer showed that:
“Infectious entities, extractable, with phosphate buffer, from tissue infected with potato spindle tuber virus and inciting symptoms on tomato that are typical of this virus, have properties incompatible with those of conventional virus particles. …[Their properties] suggest that the extractable infectious agent may be a double-stranded RNA.”
By 1971 Diener had determined that
“…the infectious RNA occurs in the form of several species with molecular weights ranging from 2.5 × 104 to 1.1 × 105 daltons. No evidence for the presence in uninoculated plants of a latent helper virus was found. Thus, potato spindle tuber “virus” RNA, which is too small to contain the genetic information necessary for self-replication, must rely for its replication mainly on biosynthetic systems already operative in the uninoculated plant.”
This was a revolutionary concept: an infectious, pathogenic entity in the form of a naked RNA that was too small to encode a replicase or any other protein. He proposed the term “viroid” to designate this and similar agents, a term that persists up to today. By 1979, they were known to be single-stranded circular RNA molecules with a high degree of sequence self-complementarity, which results in them appearing as “highly base-paired rods”.
Reverse transcription and tumour viruses
While it was apparent in the 1960s that there were single-and double-stranded DNA and RNA viruses, it was only in 1970 that two back-to-back papers in Nature, by Howard Temin and S Mituzami, and David Baltimore respectively, revealed a highly novel viral replication strategy. They showed that “RNA tumour viruses” such as the agents found by Ellerman and Bang and Peyton Rous contained an enzyme activity named reverse transcriptase – a colloquial term for RNA-dependent DNA polymerase – in their virions, which converted the single-stranded RNA genomes into double-stranded DNA. Later this was shown to result in resulted in insertion of the DNA into the host cell genome, vindicating Howard Temin’s 1960 proposal that “…a RNA tumor virus can give rise to a DNA copy which is incorporated into the genetic material of the cell”.
When Francis Crick formulated his ”Central Dogma” in 1956, it was indisputable that genetic information flowed from DNA to progeny DNA, from DNA to RNA, and from messenger RNA to protein – while he only postulated no return information flow from protein, it was generally assumed that this was also true for RNA.
In the words of David Baltimore, in his Nature article:
“Two independent groups of investigators have found evidence of an enzyme in virions of RNA tumour viruses which synthesizes DNA from an RNA template. This discovery, if upheld, will have important implications not only for carcinogenesis by RNA viruses but also for the general understanding of genetic transcription: apparently the classical process of information transfer from DNA to RNA can be inverted.”
This gives rise to a modified Central Dogma, where information flows from DNA to DNA, from DNA to RNA, from RNA to RNA, from RNA to DNA, and from RNA to protein. It is interesting that RNA seems central to this flow – which, incidentally, strengthens the proposal that RNA is the original genetic material.
Baltimore and Temin both received a share of the Nobel Prize in Physiology or Medicine 1975 for their discovery of reverse transcriptase – and shared it with Renato Dulbecco, who was credited with clarifying the process of infection and of cellular transformation by DNA tumour viruses. He used the double-stranded (ds) DNA polyomavirus SV40: this was originally isolated from monkeys, but shown to cause a variety of tumours in a number of experimental animals, hence the name “poly-oma”.
He and colleagues showed that polyomavirus grew and could be assayed normally in certain cell cultures, but caused tumour-like transformation of cells in others in which it did not grow. They showed that transformed cell chromosomes contained covalently integrated viral DNA termed a provirus, which was active in producing mRNA which made virus-specific proteins. Thus, his work was the first to show how DNA viruses might cause cancer, and he and his colleagues deserved their award “…for their discoveries concerning the interaction between tumour viruses and the genetic material of the cell.”
Viral genome cloning and sequencing: the new age
The techniques of recombinant DNA technology – or the artificial introduction of genetic material from one organism into the genome of another – were pioneered between 1971 and 1973 by Paul Berg, Herbert Boyer and Stanley Cohen. In 1971 Berg performed an in vitro exercise in which a segment of the lambda phage genome was ligated into the purified DNA of SV40, which had been linearised using the then-new restriction endonuclease, EcoRI. Cohen, Annie Chang, Boyer and Robert Helling took the technology further in 1973 by showing that:
“The construction of new plasmid DNA species by in vitro joining of restriction endonuclease-generated fragments of separate plasmids is described. Newly constructed plasmids that are inserted into Escherichia coli by transformation are shown to be biologically functional replicons that possess genetic properties and nucleotide base sequences from both of the parent DNA molecules.”
Cloning had arrived – made possible in part by use of viruses. The fundamental nature of this advance of molecular biology was rewarded by a half share of the 1980 Nobel Prize in Chemistry to Paul Berg.
Nucleotide sequencing, or the determination of the order of bases in nucleic acids, started with laborious, difficult techniques such as the two-dimensional fractionation of enzyme digests of 32P-labelled for RNA described by Frederick Sanger and colleagues in 1965. DNA sequencing followed in 1970: Ray Wu described the use of E coli DNA polymerase and radiolabelled nucleotides to sequence the single-stranded ends of phage lambda DNA. He and colleagues followed this with a more general method in 1973, using extension of synthetic oligonucleotide “primers” annealed to target DNA.
Walter Gilbert and Allan Maxam published in February 1977 an immediately popular paper entitled “A new method for sequencing DNA”. This became known as Maxam-Gilbert sequencing, or the chemical method, as it entailed sequencing by chemical degradation. Also in 1977, however, Frederick Sanger and colleagues adapted the Wu technique to come up with the so-called Sanger method, or “DNA sequencing with chain-terminating inhibitors“: this soon became the industry standard for at least the next twenty years, because it was easier and cheaper than the chemical method.
Gilbert and Sanger were awarded a share of the Nobel Prize in Chemistry in 1980, “for their contributions concerning the determination of base sequences in nucleic acids“.
MS2 phage sequencing
A highlight of Ed Rybicki’s introduction to the world of viruses was discovering during his Honours year in 1977, the paper in Nature in 1976 by Walter Fiers and his coworkers on completing the genome sequencing of the ssRNA E coli phage, MS2. They had previously also been responsible for the first ever gene sequence, in 1972: this was of the coat protein gene from the same virus. This was a landmark publication, because it completed the work of years by their group by sequencing the replicase gene, using the ribonuclease digestion and genome fragmentation and two-dimensional electrophoresis technique from Sanger. Moreover, they proposed a secondary structure for the replicase gene based on intrasequence complementarity, and described it eloquently as follows:
“The secondary structure of the coat gene resembles a flower, and there are similar foldings in other parts of the molecule; the secondary structure of the whole viral RNA therefore constitutes a bouquet”.
Their achievement looks modest in retrospect, in this era of high-throughput sequencing – however, it is worth remembering that at this time in 1976,
“MS2 is the first living organism for which the entire primary chemical structure has been elucidated”.
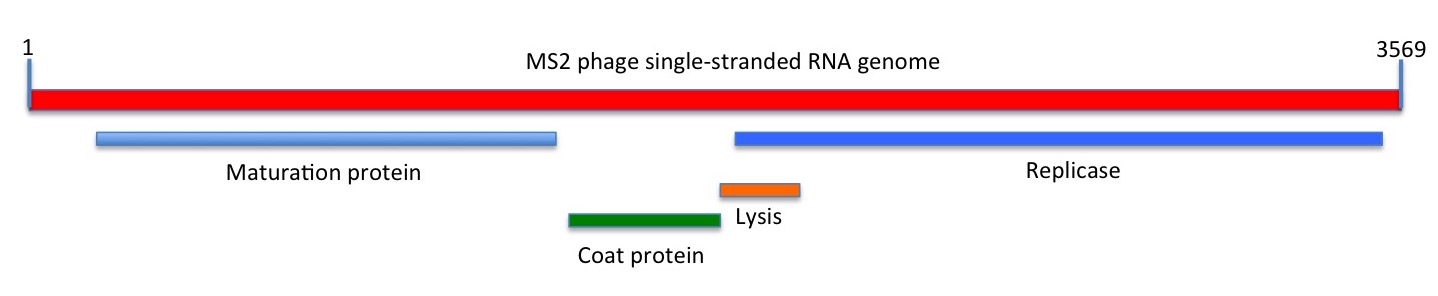
Depiction of the linear sequence of MS2 phage. The maturation (M), coat (CP) and replicase (Rep) genes and proteins were known at the time of sequencing; the lysis gene that partially overlaps the Rep open reading frame was shown to be functional only in 1982
While this comprised just 3569 nucleotides, encoding only three genes, this is sufficient to constitute a self-replicating entity with an independent evolutionary history.
The immediate value of their work was that it provided a basis for understanding the biology of the interaction of the genome with the bacterial cell at the molecular level. Moreover, the proposed secondary structures also helped explain how such a simple genome managed to temporally regulate its own expression – by means of long-distance interactions between different areas of the sequence.
PhiX174 phage sequencing
The next complete viral genome sequenced was that of the circular single-stranded DNA coliphage PhiX174, in 1977 by Sanger and his team in Cambridge, using the new sequencing technique invented by them. The abstract of their paper reads:
“A DNA sequence for the genome of bacteriophage phi X174 of approximately 5,375 nucleotides has been determined using the rapid and simple ‘plus and minus’ method. The sequence identifies many of the features responsible for the production of the proteins of the nine known genes of the organism, including initiation and termination sites for the proteins and RNAs. Two pairs of genes are coded by the same region of DNA using different reading frames.“
This was the first complete genome sequenced for any DNA-containing organism, and a satisfying conclusion to many decades of work on the virus. One of the most interesting features of the sequence was the fact that several of the 11 genes are highly overlapping: that is, the same DNA sequence is used to encode completely different genes in different open reading frames. This represented an economy of use of genetic information that was hitherto unknown.
Ed Rybicki was also able to greatly impress his Honours external examiner – one DR Woods – by launching into a detailed account of the sequencing and the genetic implications, when asked “What did you find interesting in the literature this year?”
SV40 sequencing
The simian vacuolating virus 40, or SV40, was discovered in 1960 by Ben Sweet and Maurice Hilleman as a contaminant of live attenuated polio vaccines made between 1955 and 1961: this was as a result of use of vervet or African green monkey cells that were inadvertently infected with SV40 to grow up the polioviruses. As a consequence, between 1955 and 1963 up to 90% of children and 60% of adults – 98 million people – in the USA were inadvertently inoculated with live SV40. Given the demonstration by Bernice Eddy and others in 1962 that hamsters inoculated with simian cells infected with SV40 developed sarcomas and ependymomas, the class of viruses including SV40 and MPyV described earlier became known as “polyomaviruses”, and DNA tumour viruses. However, and despite considerable concern over many years, SV40 has not been shown to cause or to definitively be associated with any human cancers.
Still, it had become an object of considerable interest as mentioned earlier in connection with Renato Dulbecco, and it was accordingly the next virus to be completely sequenced. This was by Walter Fier’s group: they determined by Maxam-Gilbert sequencing that the circular dsDNA genome comprised 5224 base pairs, and had an interesting organisation. In their words:
“Particular points of interest revealed by the complete sequence are the initiation of the early t and T antigens at the same position and the fact that the T antigen is coded by two non-contiguous regions of the genome; the T antigen mRNA is spliced in the coding region. In the late region the gene for the major protein VP1 overlaps those for proteins VP2 and VP3 over 122 nucleotides but is read in a different frame.”
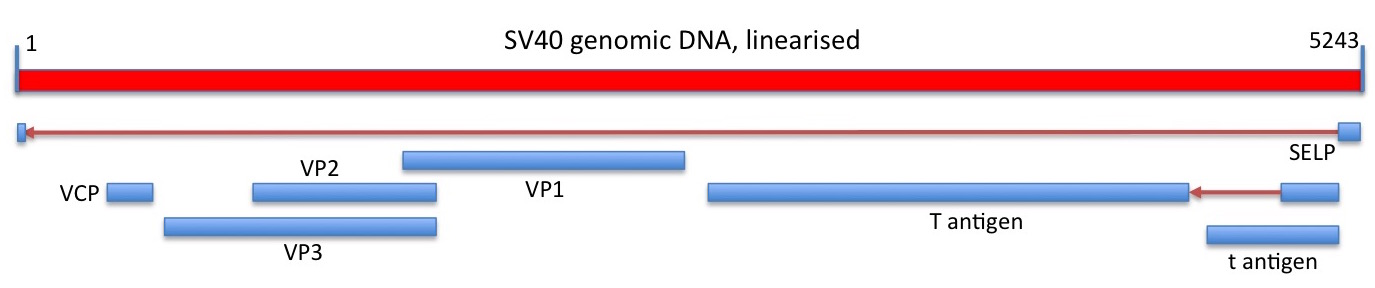
Linear depiction of the circular SV40 genome and its protein coding capacity. Regions of RNA spliced out of of transcribed genomic sequence, and the direction of transcription, are shown as red arrows. Genes shown are those depicted in the current Genbank sequence entry.
This was the first time that RNA splicing had been demonstrated for an entire genome; indeed, it had only been discovered in 1977 when two separate groups of researchers showed that adenovirus-specific mRNAs made late in the replication cycle in cell cultures were mosaics, being comprised of sequences from noncontiguous or separated sites in the viral genome. This was subsequently found to be a common feature in eukaryotic but not prokaryotic mRNAs.
The SV40 genome showed major gene overlaps, as for the PhiX174, again demonstrating the effectiveness with which viruses could pack protein coding capability into a small genome.
Sequencing of a viroid
Also in 1978, Heinz Sänger’s group published the sequence and the predicted secondary structure of potato spindle tuber viroid. This was the first RNA genome to be sequenced using the still relatively new method of generating complementary DNA (cDNA) from RNA by use of reverse transcriptase.
They stated in their Nature paper abstract that:
“PSTV is the first pathogen of a eukaryotic organism for which the complete molecular structure has been established”.
This was absolutely true, as the detailed 3D structure of SV40 was not known, even though the genome sequence was.
Sequencing of the first human polyomavirus
In October and December of 1979, two groups published the complete nucleotide sequences of two strains of the polyomavirus known as BKV: this had been first isolated from a renal transplant patient with those initials in 1971, and found to be present in about 80% of healthy blood donors. It causes only mild infections – fever and respiratory symptoms – on first infection, and then subsequently infects cells in the kidneys and urinary tract, where it can remain causing no symptoms for the lifetime of infected individuals. It is associated with renal dysfunction in immunocompromised people, and “BK nephropathy” in transplant patients, when immunosuppressive drugs allow destructive viral multiplication within the donated organ.
The viral sequences differed by 190 nucleotides from one another, and the first-published MM strain sequence was shown to have a strikingly similar arrangement of putative genes to SV40, and to share 70% sequence homology and 73% predicted amino acid sequence homology with SV40. It also shared 75% genome sequence homology with the JC polyomavirus, first isolated in 1971 from a patient with progressive multifocal leukoencephalopathy (PML). It is found in between 70 and 90% of humans, but as with BKV, is only associated with disease in immunosuppressed or immunodeficient people.
The hepatitis B virus genome
The involvement of HBV in human disease has already been described, as has its potential to cause human cancers. The complete genome sequence of an E coli genomic clone of the “subtype ayw” strain of HBV was reported by Francis Galibert and co-workers in 1979. This consisted of 3182 nucleotides, arranged as what had previously been shown by physicochemical techniques on DNA isolated from virions to be a circular structure with a “-” strand with a short gap, and an incomplete “+” strand of varying length. The reason for this was puzzling, and was attributed to virion assembly requirements, although the covalently closed circular form of this and related viruses (duck hepatitis), like genomes of polyoma- and papillomaviruses, had been isolated. The reason for this would have to wait a few years, and would result in a new class of viruses being recognised that would reflect very deep evolutionary links between viruses and cellular elements.
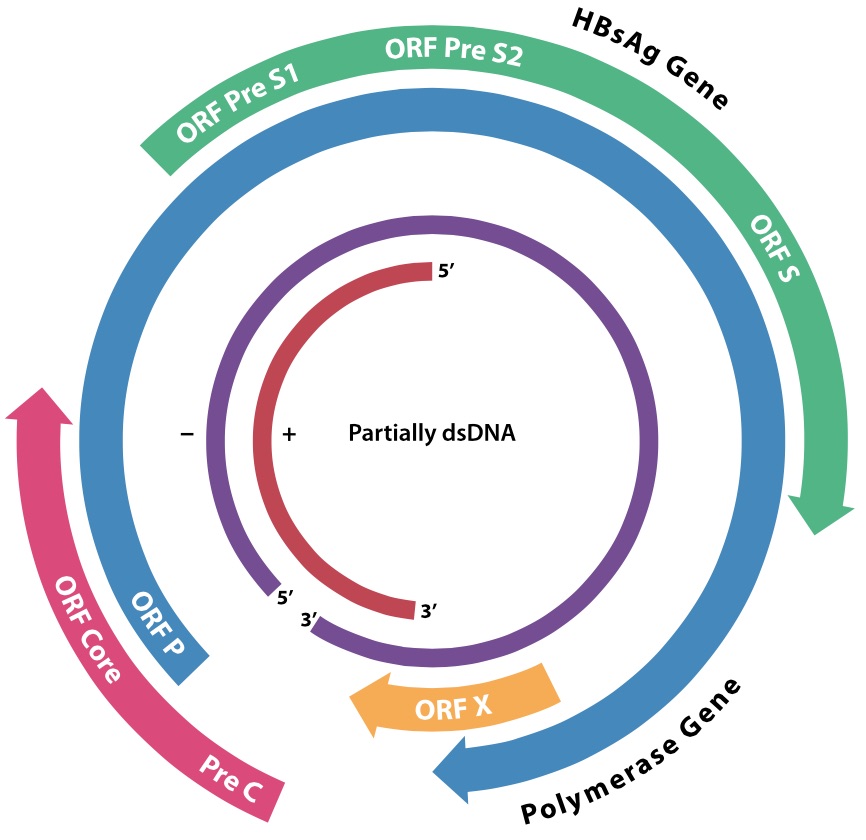
The HBV genome.
“HBV Genome” by T4taylor – Own work based on File:HBV_genome.png. Licensed under CC BY-SA 3.0 via Wikimedia Commons – http://commons.wikimedia.org/wiki/File:HBV_Genome.svg#/media/File:HBV_Genome.svg
Cauliflower mosaic virus
The first of what are now known to be caulimoviruses – family Caulimoviridae – was described in 1933 as dahlia mosaic virus. Cauliflower mosaic virus (CaMV) was described in 1937, and shown to have particles containing a DNA genome in 1968. This was visualised by electron microscopy by two groups in 1971 as relaxed open circles or also as linear forms – unlike the supercoiled DNAs of papilloma- or papovaviruses. By 1977 it was known that the “nicked circular form” was infectious, and fragments of the genome had been cloned in E coli. Physical and biochemical characterisation of the genome in 1978 showed that it consisted of three discrete lengths of single-stranded DNA – alpha, beta and gamma, with alpha being the full genome-length – that annealed to one another to give a circular double-stranded form about 8 000 nucleotides in length. By 1979 it was known that only the alpha strand was transcribed to give mRNA.
The complete sequence of the viral genome was published in 1980, and was predicted to encode six proteins: this has since been upped to eight, with two small ORFs (VII and VIII) being shown to produce proteins. The genome is transcribed into only two mRNAs – named 35S and 19S, on the basis of their sedimentation properties – and contains one discontinuity in the alpha or coding strand, and two in the non-coding sequence. Cloned DNA was also shown to be infectious in 1980, even if excised as a linear molecule.
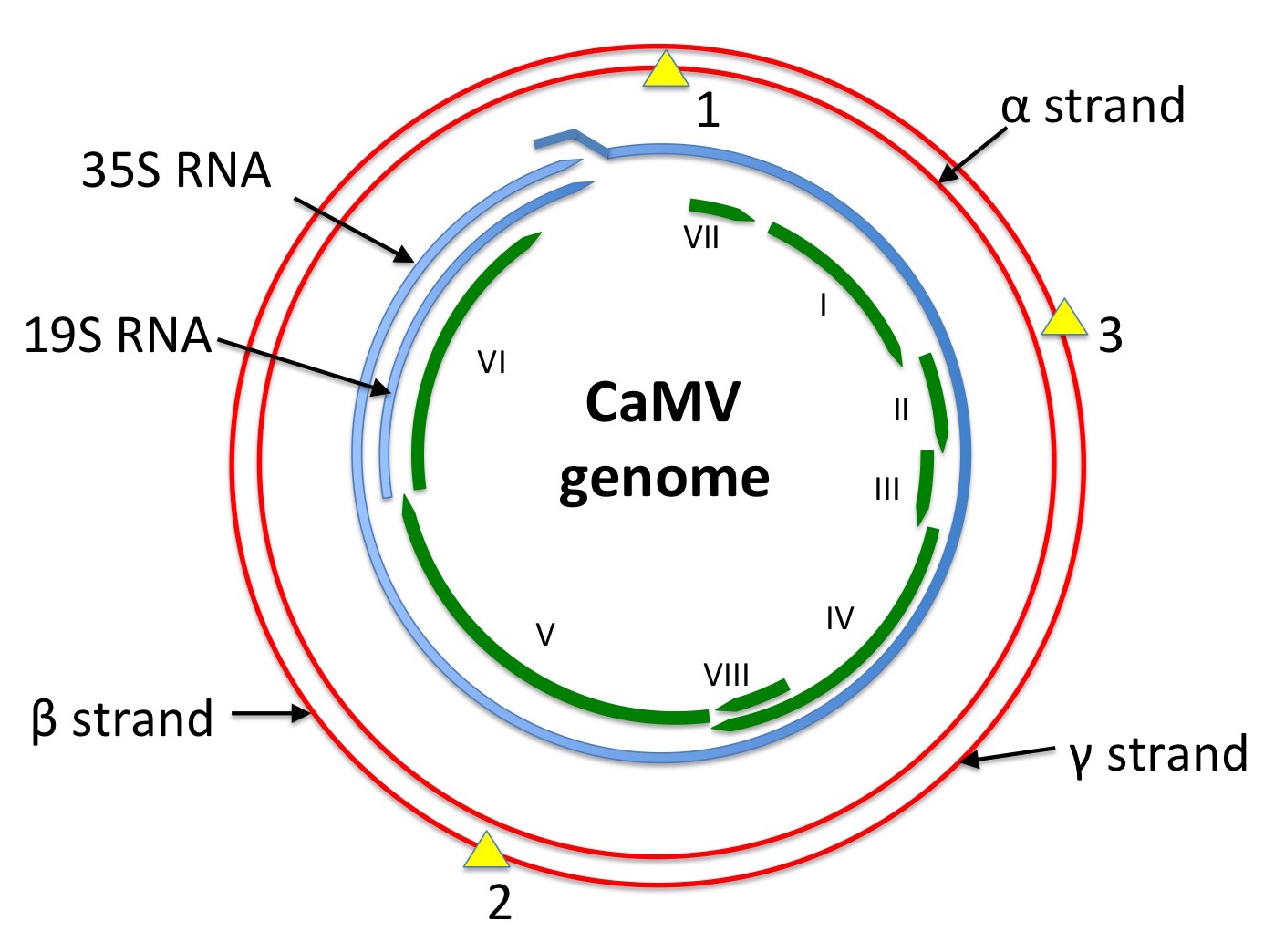
Diagram showing a depiction of the CaMV genome in red, with single-strand discontinuities shown as yellow triangles. mRNA species are shown in blue: the 35S RNA is longer-than-genome-length, with a ~200 bp repeat at the 5’ and 3’ ends. ORFs as presently known are shown in green.
Redrawn from Figure 8.1 of REF Mathews’ “Plant Virology”, 3rd edition.
A new class of viruses
In 1971, David Baltimore of reverse transcriptase and future Nobel Prize fame published a review in which he described the “Expression of Animal Virus Genomes” as it was then understood. This described a scheme for classifying viruses on the basis of the pathways taken to make messenger RNA – because, in his words,
“The specific mechanism for mRNA synthesis used by a given virus depends on the structure of the viral genetic material”,
which in turn meant that the different means used to arrive at the same end were useful in functionally grouping viruses together.
He proposed 6 classes of viral expression. These were:
- Class I: all dsDNA viruses
- Class II: ssDNA viruses
- Class III: dsRNA viruses
- Class IV: ssRNA viruses whose mRNA sequences are subsets of the virion RNA sequence (ie: ss(+)RNA viruses)
- Class V: ssRNA viruses with genomes which are complementary in sequence to the mRNA sequences (ie: ss(-)RNA viruses)
- Class VI: ssRNA viruses which have a DNA intermediate in their lifecycle
It is worth remembering that this was proposed only for animal viruses, and that it was not even known at the time whether retroviruses (Class VI) actually made a DNA genome in cells or what their mRNA looked like. Additionally, remembering that this predated both cloning and sequencing of viral genomes or mRNAs, it was a triumph of biochemistry and molecular biology at the time that as much as was known. For example, it was only discovered in 1968 that dsRNA-containing reovirus particles also contained an RNA polymerase activity. Baltimore himself only discovered in 1970 that the ssRNA-containing vesicular stomatitis virus virions also contained an RNA polymerase. He made the simple but bold and prescient proposition that:
“The discovery of virion [RNA-dependent RNA] polymerases has provided a rationale for an old puzzle in virology. Why is it that infectious nucleic acid can be extracted from the virions of some viruses but not others? Virion polymerases provide the clue to this puzzle; where they exist the nucleic acid is noninfectious, where the nucleic acid is infectious they could not exist or at least they could not serve an obligate role.”
This has held up surprisingly well, to the extent that the Baltimore Classification has been enshrined in the teaching of virology – by me, among others – for more than 40 years, and has been extended to cover all viruses, as the similarities in their route to mRNA synthesis became apparent, whether they infected bacteria, animals or plants. In light of the discovery detailed below, it is interesting that HBV virions were discovered in 1975 to contain both circular dsDNA and a DNA polymerase activity. The virion DNA pol could be used in vitro to convert the partially-dsDNA to a 3 kb completely dsDNA.
Baltimore also wisely made room for “…extending the class designations”, which meant that a very important new class of viruses could be neatly slotted in as Class VII, after their confirmation in 1983. These were dsDNA viruses which have an RNA intermediate in the life cycle, or pararetroviruses as they came to be known – and the first two representatives were the very different duck hepatitis B virus (DBV) and CaMV, which had been thought of up till then as classical dsDNA viruses.
DBV was discovered in 1980, then investigated by Jesse Summers and William Mason, who determined in 1982 that:
“Subviral particles resembling the viral nucleocapsid cores were isolated from persistently infected liver and shown to have a DNA polymerase activity that utilizes an endogenous template and synthesizes both plus- and minus-strand viral DNA. Synthesis of the viral minus-strand DNA utilized an RNA template that was degraded as it was copied. Viral plus-strand synthesis occurred on the completed minus-strand DNA”.
On the basis of this evidence, they proposed a pathway for replication of HBV-like viruses by reverse transcription of a RNA intermediate.
The next member of the reverse transcribing Class VII pararetroviruses was described in 1983, by Pierre Pfeiffer and Thomas Hohn. Interestingly, like retroviruses and unlike the very different HBV model, their model for CaMV replication included a probable tRNA primer for RNA-dependent DNA synthesis initiation. It is also interesting that CaMV virions did not contain a DNA polymerase activity, unlike HBVs or retroviruses, indicating significant differences in the mode of replication. However, the demonstration in 1983 of amino acid sequence homology between the retroviral reverse transcriptase and putative polymerases of both HBV and CaMV, cemented the dawning realisation of a whole new class of viruses.
Ed Rybicki remembers vividly the excitement at the Seventh John Innes Symposium in 1986 on “Virus replication and genome interactions”, where evidence was presented for both HBV and CaMV – and strong public disbelief expressed as to whether HBV replicated by this route by none other than Peter Duesberg, who later went on to also doubt that HIV caused AIDS.
Infectious, cloned poliovirus RNA
In 1958, working from the example of Gierer and Scramm with TMV, Hattie Alexander and colleagues demonstrated that RNA extracted from concentrated, partially purified preparations of polioviruses types I and II, that was free of protein and DNA, was infectious in cultured HeLa cells and human amnion cell monolayers. Moreover, the RNA produced progeny virus characteristic of that used to produce the RNA. The concept of RNA genomes was still new enough at the time to prompt their conclusion that:
“It would seem, therefore, that the virus RNA is the essential infectious agent”.
In the same year, the same was shown by Fred Brown for another distantly related picornavirus, foot and mouth disease virus. By 1968, it was known – thanks to MF Jacobson and Baltimore and others – that several picornaviruses related to poliovirus appeared to have just one open reading frame (ORF) encoding a single polypeptide encoded in their genomic RNA, and did not make a smaller mRNA.
In June of 1981, Naomi Kitamura and coworkers published the complete nucleotide sequence of poliovirus I. They showed it was
“[an] RNA molecule [which] is 7,433 nucleotides long, polyadenylated at the 3′ terminus, and covalently linked to a small protein (VPg) at the 5′ terminus. An open reading frame of 2,207 consecutive triplets spans over 89% of the nucleotide sequence and codes for the viral polyprotein NCVPOO”.
In August 1981, Vincent Racaniello – working in Baltimore’s lab – reported a set of three cDNA clones in E coli spanning the whole of the poliovirus I genome, and also sequenced the genome.
Later in 1981, Racaniello used the three clones to construct one contiguous cDNA clone in pBR322, which he successfully used to transfect vervet monkey (=African green monkey) kidney cell cultures, producing infectious wild-type virus with which he produced characteristic plaques in HeLa cells. This was the first proof that an infectious cDNA construct could be made for an RNA virus – and it is interesting that the construct should not have worked, as there was no mammalian promoter to produce the viral RNA, and it had to rely on an adventitious or cryptic promoter in the plasmid sequence. In any case, it was an excellent example of success of the “just try it” school of experimentation. He has written an excellent account of this – “Thirty years of infectious enthusiasm” – in his popular blog.
Tobacco mosaic virus sequenced
In 1982, P Goelet and five coworkers published the complete nucleotide sequence of the Vulgare strain of tobacco mosaic virus. They did this by using reverse transcriptase and synthetic oligonucleotide primers to generate a set of short, overlapping complementary DNA fragments covering the whole TMV genome, cloning these in bacteriophage M13, and using the Sanger dideoxy method to determine the sequences :…of more than 400 independently derived cDNA clones”. Their complete sequence confirmed earlier partial sequences derived by direct RNA sequencing techniques, as well as confirming quite pronounced sequence variability within the isolate, especially at the 5’ end.
The length of the consensus sequence they produced has to be dug for in the paper, incidentally, as nowhere do the authors in fact simply state what it is – or in fact give a diagram of the genetic organisation!
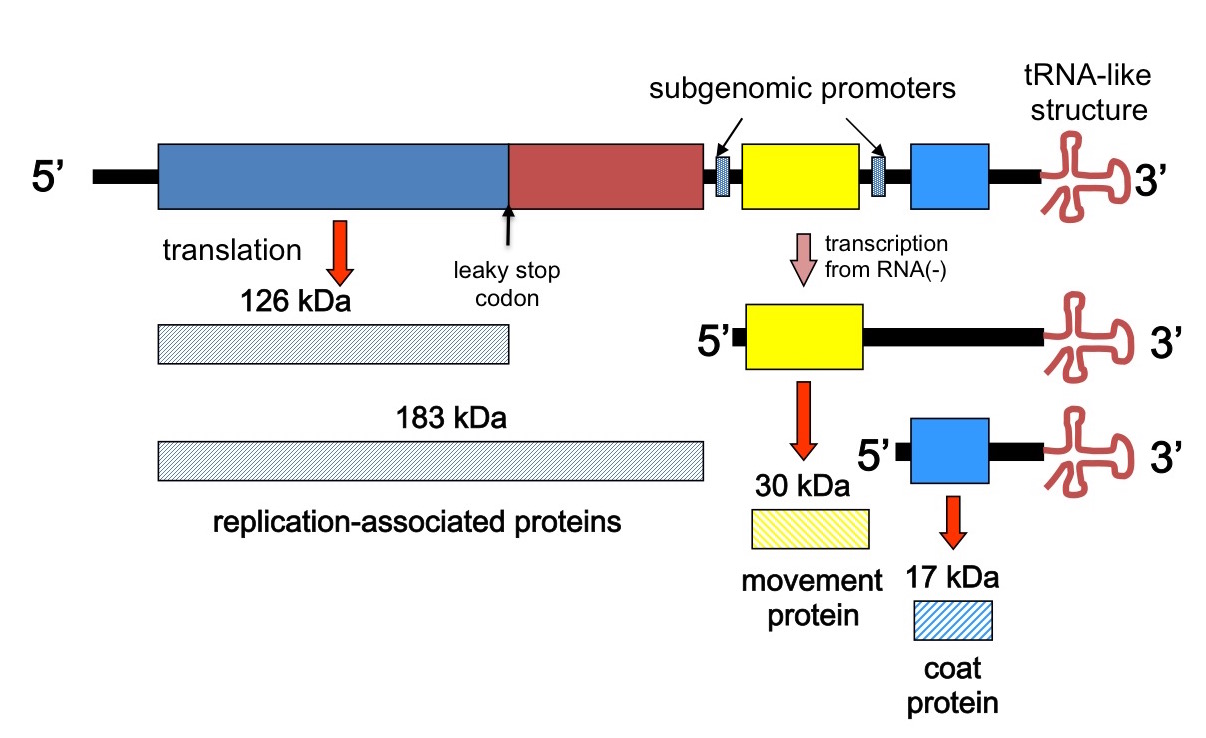
Depiction of the TMV genome and transcription and translation strategy
They report a 6 395 nucleotide sequence, with just three major ORFs. However, the presence of an amber or leaky stop codon explained how two different N-coterminal proteins could be made by translation of genomic RNA, and separate ribosome binding sites for the two genomic 3’ ORFs plus the already proven existence of subgenomic 3’-coterminal mRNAs, explained how the other proteins could be made. Their was also found to be a unique hairpin loop-encoding sequence region for assembly initiation – nicely rounding out pioneering work by PJ Butler and colleagues and Genevieve Lebeurier and others – both published in January 1977, incidentally – on the physical mechanism of assembly, which had shown a single site for assembly nucleation.
The circle closes: TMV understood
The sequencing of TMV almost, but not quite, brought to a complete circle the journey of discovery that started with its description as a “contagium vivum fluidum” in 1898. Closing the circle required a complete molecular understanding of the virus particle, which was achieved with the publication from Gerald Stubbs’ group of the 3.6 Angstrom resolution structure for TMV in 1986, and then the refined 2.9 A structure in 1989. In their words,
“The final model contains all of the non-hydrogen atoms of the RNA and the protein, 71 water molecules, and two calcium-binding sites.”
This allowed the building of molecular models that helped explain the chemical and physical basis for virion self-assembly, as well as accounting for the positioning in particles of the whole RNA and the whole of the more than 2000 individual protein subunit sequences.
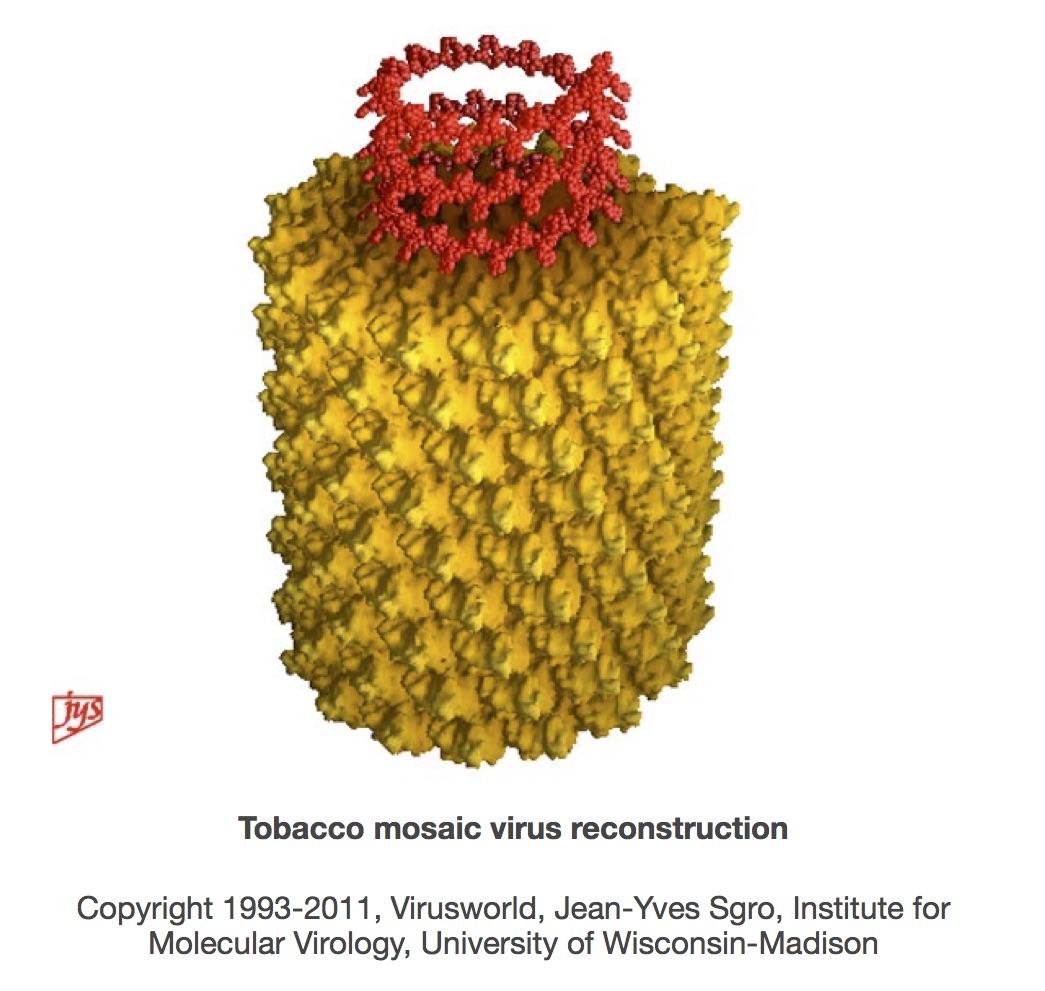
The structure also brought to a conclusion a journey that had started as early as 1936, after Stanley’s demonstration that TMV could be crystallised. Gerald Stubbs has written an excellent account in the book “Tobacco Mosaic Virus: One Hundred Years of Contributions to Virology” of how JD Bernal and I Fankuchen used “liquid crystalline” gels of TMV provided by Bawden and Pirie, and RWG Wyckoff and RB Corey used crystals of TMV, to obtain X-ray diffraction patterns. While Bernal and Fankuchen were not able to do more than obtain the radius of the virions, and the dimensions of the protein subunits as well as their repeat along the virion axis, they laid the foundations for others to work not only on helical viruses, but also on DNA and RNA helices.
Rosalind Franklin of DNA structure fame took on the study of TMV structure using the then-new method of isomorphous replacement to first, in 1956, locate the RNA within virions, and then in 1958 with Kenneth Holmes, to determine that the virions were indeed helical in structure – something first proposed by James Watson in 1954, although he did not see they were also hollow. Indeed, Crick and Watson used her TMV structure results to bolster their proposal in 1956 that virions of small viruses were built up according to simple rules of symmetry from identical protein subunits surrounding the nucleic acid.
Franklin died in 1958, which may have denied her a share of the Nobel Prize for the structure of DNA that went to Watson, Francis Crick and Maurice Wilkins in 1962.
Holmes and Stubbs continued the work on TMV, however, and published a 6.7 A structure in 1975: this showed that an 11 A structure seen by Bernal and Fankuchen in 1936 was in fact alpha helices within subunits. They went on with Steven Warren in 1977 to obtain a 4 A structure which showed the structure of RNA and the RNA binding site of the protein. Stubbs celebrated his group’s subsequent refinements of the structure with this statement in the centenary book on TMV:
“…in 1989, Bernal and Fankuchen’s remarkable patterns finally yielded the fulfillment of Franklin’s vision with the publication of the 2.9 A resolution structure…”
A modest statement for a landmark achievement: the finalising of the complete molecular understanding of the first virus discovered. The circle was finally closed, 91 years after Beijerinck first showed how a filter could define a new class of organisms.
See here for a TMV Timeline
Click here for Part 1: Filters and Discovery
here for Part 2: The Ultracentrifuge, Eggs and Flu
here for Part 3: Phages, Cell Culture and Polio
Copyright Edward P Rybicki and Russell Kightley, February 2015, except where otherwise noted.

{kind=link}